本文档讲解如何在期魔方量化交易平台使用机器学习交易策略,其中涉及到机器学习模型的训练、评估、可视化,模型保存和加载。还会讲解如何将训练好的模型放到交易策略中进行策略的回测和实盘交易。
机器学习在量化交易领域的应用前景广阔。随着计算能力的提升和算法的进步,机器学习正在重塑传统的交易方式。它能够从海量市场数据中捕捉到人工难以发现的微妙关联和交易机会,为量化交易带来新的突破:
未来,随着人工智能技术的发展,机器学习在量化交易中的应用将更加深入和普及,有望成为投资领域的重要竞争力。
机器学习在期货量化交易中展现出巨大潜力,而期魔方作为专业的量化交易平台,为交易者提供了独特的优势。通过期魔方进行机器学习,可以充分利用平台海量的历史行情数据和实时市场信息,构建更精准的预测模型。平台内置的数据清洗、特征工程等功能大大简化了数据预处理环节,让交易者可以专注于策略开发。
期魔方的主要优势包括:
对于小白用户来说,机器学习量化交易有一定的入门门槛,具体如下:
入门门槛:
快速上手建议:
大模型时代的到来,机器学习策略的门槛已经大大降低,小白用户完全可以通过平台提供的工具,逐步掌握这项技能。
期魔方机器学习功能可以由用户自由定制,充分利用 Python 强大的 AI 生态体系,包括但不限于使用 scikit-learn 等经典机器学习框架,后续还将支持 PyTorch 等深度学习框架。 由于机器学习模型众多,为了尽量降低入门门槛,下面以期魔方提供的【经典机器学习模型-线性回归】的案例为例,来说明期魔方平台机器学习的使用。
这是期魔方提供的【经典机器学习模型-线性回归】的案例代码,主要使用机器学习中的线性回归模型来预测螺纹钢期货价格。 线性回归是一种监督学习算法,用于建立一个或多个自变量(特征)与因变量(目标变量)之间的线性关系。
在这个模型中,特征是指用于预测目标变量的输入变量。具体来说:
目标变量是指模型试图预测的输出变量。在这个模型中:
"""
文件类型:机器学习
帮助文档:https://qmfquant.com/static/doc/code/modelEdit.html
期魔方,为您提供专业的量化服务
模型类型:经典机器学习模型-线性回归
"""
import asyncio
import os
import joblib
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import qmf_model_sdk
import seaborn as sns
from qmf_data import load_kline
from scipy import stats
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 获取数据配置
symbol = "rb888"
begin_time = "2020-01-01"
end_time = "2025-05-01"
symbol_cycle = "1天"
asyncio.run(qmf_model_sdk.get_futures_data(symbol, begin_time, end_time, symbol_cycle))
symbol = "i888"
asyncio.run(qmf_model_sdk.get_futures_data(symbol, begin_time, end_time, symbol_cycle))
# 设置图形、中文及负号显示
matplotlib.use("QtAgg") # 期魔方平台图形显示必须要有这行代码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 获取螺纹钢主连和铁矿石主连的数据
def get_futures_data(symbol, start_time="2023-01-01 00:00:00", end_time="2025-05-01 00:00:00"):
data = load_kline(product=symbol, cycle="1D", start_time=start_time, end_time=end_time)
data["date"] = pd.to_datetime(data["date"], errors="coerce")
data.rename(columns={"close": "收盘"}, inplace=True)
data.reset_index(inplace=True, drop=True)
return data
# 获取保存模型文件的地址
def get_save_model_path(file_name):
current_file_path = os.path.abspath(__file__)
filename_without_ext = os.path.splitext(os.path.basename(current_file_path))[0]
return f"{os.path.dirname(current_file_path)}\\{filename_without_ext}__{file_name}"
# 获取数据
rbm_data = get_futures_data("rb888") # 螺纹钢主连
im_data = get_futures_data("i888") # 铁矿石主连
# 合并数据,基于日期,这样可以确保铁矿石和螺纹钢数据对齐
df = pd.merge(
rbm_data[["date", "收盘"]],
im_data[["date", "收盘"]],
on="date",
how="inner",
suffixes=("_螺纹钢", "_铁矿石"),
)
# 创建前一天的铁矿石价格列
df["前一天铁矿石收盘"] = df["收盘_铁矿石"].shift(1)
# 删除第一行,因为它没有前一天的数据
df = df.dropna()
# 建立预测模型,利用前一天铁矿石的价格预测当天螺纹钢的收盘价
X = df[["前一天铁矿石收盘"]].values
y = df["收盘_螺纹钢"].values
# 确保数据按时间排序
df = df.sort_values("date")
# 按时间顺序划分训练集和测试集(80%训练,20%测试)
train_size = int(len(df) * 0.8)
train_data = df.iloc[:train_size]
test_data = df.iloc[train_size:]
# 准备特征和目标变量
X_train = train_data[["前一天铁矿石收盘"]].values
y_train = train_data["收盘_螺纹钢"].values
X_test = test_data[["前一天铁矿石收盘"]].values
y_test = test_data["收盘_螺纹钢"].values
# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 在训练集和测试集上进行预测
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 计算各种评估指标
def calculate_metrics(y_true, y_pred):
r2 = r2_score(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_true, y_pred)
mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100
return r2, rmse, mae, mape
# 计算训练集和测试集的评估指标
train_metrics = calculate_metrics(y_train, y_train_pred)
test_metrics = calculate_metrics(y_test, y_test_pred)
# 打印评估结果
print("\n模型评估结果:")
print("训练集:")
print(f"R²分数: {train_metrics[0]:.4f}")
print(f"RMSE: {train_metrics[1]:.2f}")
print(f"MAE: {train_metrics[2]:.2f}")
print(f"MAPE: {train_metrics[3]:.2f}%")
print("\n测试集:")
print(f"R²分数: {test_metrics[0]:.4f}")
print(f"RMSE: {test_metrics[1]:.2f}")
print(f"MAE: {test_metrics[2]:.2f}")
print(f"MAPE: {test_metrics[3]:.2f}%")
# 创建评估图
plt.figure(figsize=(20, 15))
# 1. 实际值vs预测值图
plt.subplot(2, 2, 1)
plt.scatter(y_train, y_train_pred, c="blue", alpha=0.5, label="训练集")
plt.scatter(y_test, y_test_pred, c="red", alpha=0.5, label="测试集")
plt.plot([y.min(), y.max()], [y.min(), y.max()], "k--", lw=2)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值 vs 预测值")
plt.legend()
# 2. 残差图
residuals_train = y_train - y_train_pred
residuals_test = y_test - y_test_pred
plt.subplot(2, 2, 2)
plt.scatter(y_train_pred, residuals_train, c="blue", alpha=0.5, label="训练集")
plt.scatter(y_test_pred, residuals_test, c="red", alpha=0.5, label="测试集")
plt.axhline(y=0, color="k", linestyle="--")
plt.xlabel("预测值")
plt.ylabel("残差")
plt.title("残差分布图")
plt.legend()
# 3. 残差直方图
plt.subplot(2, 2, 3)
sns.histplot(residuals_train, color="blue", alpha=0.5, label="训练集", bins=30)
sns.histplot(residuals_test, color="red", alpha=0.5, label="测试集", bins=30)
plt.xlabel("残差")
plt.ylabel("频数")
plt.title("残差直方图")
plt.legend()
# 4. Q-Q图
plt.subplot(2, 2, 4)
stats.probplot(residuals_train, dist="norm", plot=plt)
plt.title("残差Q-Q图")
plt.tight_layout()
plt.show()
# 5. 添加时间序列预测图
plt.figure(figsize=(15, 7))
plt.plot(train_data["date"], train_data["收盘_螺纹钢"], 'b-', label='训练集实际值')
plt.plot(train_data["date"], y_train_pred, 'g--', label='训练集预测值')
plt.plot(test_data["date"], test_data["收盘_螺纹钢"], 'r-', label='测试集实际值')
plt.plot(test_data["date"], y_test_pred, 'y--', label='测试集预测值')
plt.axvline(x=train_data["date"].iloc[-1], color='k', linestyle='--', label='训练/测试分割点')
plt.xlabel('日期')
plt.ylabel('螺纹钢收盘价')
plt.title('时间序列预测结果')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 6. 添加散点图显示铁矿石价格与螺纹钢价格的关系
plt.figure(figsize=(10, 6))
plt.scatter(train_data["前一天铁矿石收盘"], train_data["收盘_螺纹钢"],
c="blue", alpha=0.5, label="训练集")
plt.scatter(test_data["前一天铁矿石收盘"], test_data["收盘_螺纹钢"],
c="red", alpha=0.5, label="测试集")
# 添加回归线
x_range = np.linspace(
min(df["前一天铁矿石收盘"]),
max(df["前一天铁矿石收盘"]),
100
).reshape(-1, 1)
plt.plot(x_range, model.predict(x_range), 'k-', lw=2)
plt.xlabel('前一天铁矿石收盘价')
plt.ylabel('螺纹钢收盘价')
plt.title('前一天铁矿石价格与螺纹钢价格关系')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 保存模型
model_filename = get_save_model_path("经典机器学习模型-线性回归-model.qmf")
joblib.dump(model, model_filename)
print(f"模型已保存至: {model_filename}")
# 加载模型示例
loaded_model = joblib.load(model_filename)
# 使用加载的模型进行预测
test_value = np.array([[800]]) # 假设前一天铁矿石价格为 800 时
predicted_price = loaded_model.predict(test_value)[0]
print("使用加载的模型预测:")
print(f"当铁矿石前一日价格为 800 时,螺纹钢当日预测价格为: {predicted_price:.2f}")
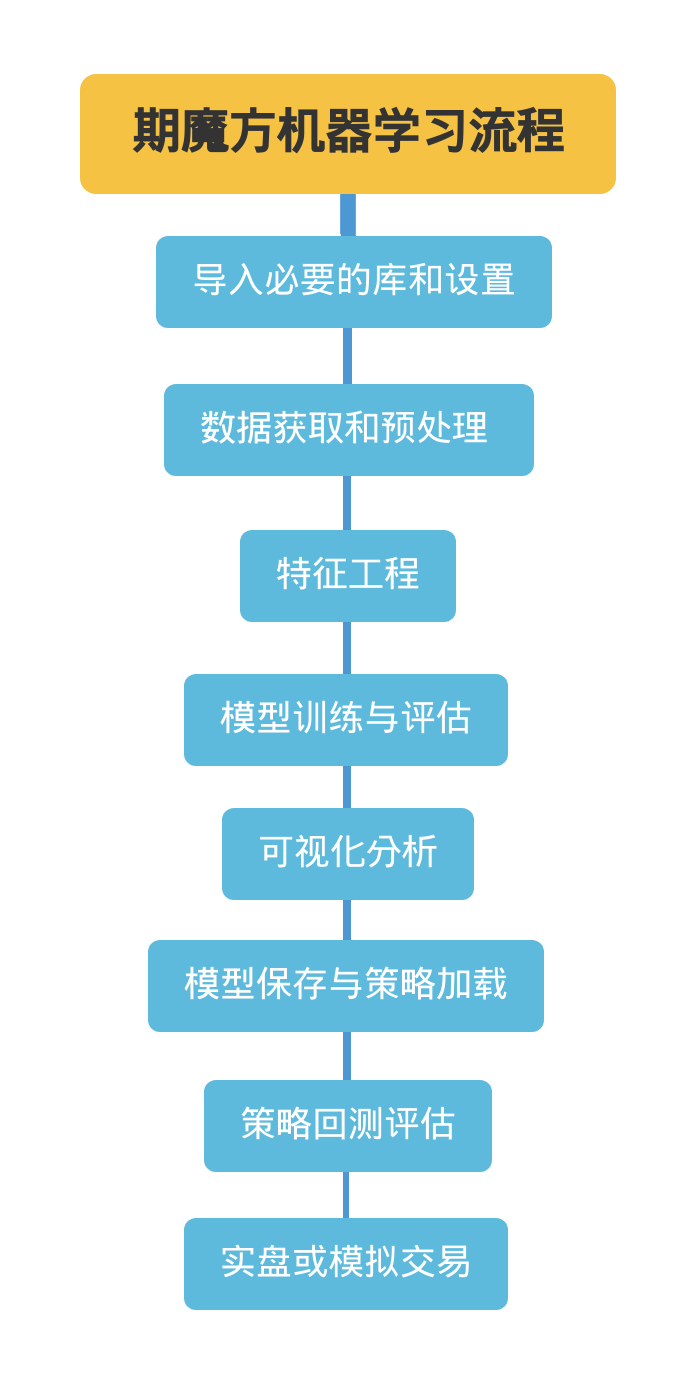
此案例及期魔方提供的其他案例,基本都可以概括为如下的几个组成部分:
在 Python 中需要使用相关的功能,就需要导入必要的库和基础的设置。在期魔方的机器学习功能中,用户可以根据需求导入相关的内置和第三方库,目前如下涉及到的库已经在期魔方系统中内置。
import pandas as pd
import numpy as np
Python 中科学计算的基础库
提供多维数组对象支持和数学函数
本案例中用于:
import matplotlib.pyplot as plt
Python 中数据可视化库
用于绘制各种统计图表
本案例中用于绘制:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
Python 中 LinearRegression 模块提供线性回归模型实现
metrics 模块: 提供模型评估指标
import joblib
Python 中提供模型持久化功能
用于保存和加载训练好的机器学习模型
本案例中用于
import seaborn as sns
import os
提供操作系统相关的功能
本案例中用于:
from scipy import stats
科学计算库 scipy 中的统计模块
本案例中用于:
matplotlib.use("QtAgg") # 期魔方平台图形显示必须要有这行代码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import qmf_model_sdk
from qmf_data import load_kline
import asyncio
这些库的组合使用,构成了一个完整的数据分析和机器学习工作流程:
首先使用 qmf_model_sdk,其中 qmf_model_sdk 是期魔方自带的库,使用方式如下:
进入策略模块,点击机器学习子模块,在右上角找到获取数据的按钮,点击该按钮会打开 VSCode 编辑器,
可以看到编辑器中已经预先写好了获取数据的代码。直接修改代码中的参数,然后保存代码,执行程序,待日志打印获取数据结束,则完成下载数据。
import asyncio
import qmf_model_sdk
from qmf_data import load_kline
"""
symbol - 合约代码
begin_time - 开始时间,格式 YYYY-mm-dd
end_time - 结束时间,格式 YYYY-mm-dd
symbol_cycle - 周期,可以选值如下:
'1分钟','3分钟','5分钟','10分钟','15分钟','30分钟','45分钟'
'1小时','2小时','4小时'
'1天','1周','1月','1季','1年'
"""
# 获取数据配置
symbol = "rb888"
begin_time = "2020-01-01"
end_time = "2025-05-01"
symbol_cycle = "1天"
asyncio.run(qmf_model_sdk.get_futures_data(symbol, begin_time, end_time, symbol_cycle))
symbol = "i888"
asyncio.run(qmf_model_sdk.get_futures_data(symbol, begin_time, end_time, symbol_cycle))
然后通过提供的 qmf_data 获取数据,并将 close 重命名为收盘
def get_futures_data(symbol, start_time="2023-01-01 00:00:00", end_time="2025-05-01 00:00:00"):
# 通过期魔方数据模块获取期货数据
data = load_kline(product=symbol, cycle="1D", start_time=start_time, end_time=end_time)
# 转换日期格式并筛选时间范围
data["date"] = pd.to_datetime(data["date"], errors="coerce")
# 重命名收盘价列
data.rename(columns={"close": "收盘"}, inplace=True)
# 重置索引
data.reset_index(inplace=True, drop=True)
return data
# 获取螺纹钢和铁矿石主力合约数据
rbm_data = get_futures_data("rb888") # 螺纹钢主连
im_data = get_futures_data("i888") # 铁矿石主连
首先合并数据,基于日期将铁矿石和螺纹钢数据对齐。然后创建前一天的铁矿石价格列,并删除第一行因为它没有前一天的数据。接下来,确保数据按时间排序,并按时间顺序将数据集划分为训练集(80%)和测试集(20%)。最终将前一天铁矿石的收盘价作为特征(X),当天螺纹钢的收盘价作为预测目标(y), 分别准备训练集和测试集的特征与目标变量。
# 合并数据,基于日期,这样可以确保铁矿石和螺纹钢数据对齐
df = pd.merge(
rbm_data[["date", "收盘"]],
im_data[["date", "收盘"]],
on="date",
how="inner",
suffixes=("_螺纹钢", "_铁矿石"),
)
# 创建前一天的铁矿石价格列
df["前一天铁矿石收盘"] = df["收盘_铁矿石"].shift(1)
# 删除第一行,因为它没有前一天的数据
df = df.dropna()
# 建立预测模型,利用前一天铁矿石的价格预测当天螺纹钢的收盘价
X = df[["前一天铁矿石收盘"]].values
y = df["收盘_螺纹钢"].values
# 确保数据按时间排序
df = df.sort_values("date")
# 按时间顺序划分训练集和测试集(80%训练,20%测试)
train_size = int(len(df) * 0.8)
train_data = df.iloc[:train_size]
test_data = df.iloc[train_size:]
# 准备特征和目标变量
X_train = train_data[["前一天铁矿石收盘"]].values
y_train = train_data["收盘_螺纹钢"].values
X_test = test_data[["前一天铁矿石收盘"]].values
y_test = test_data["收盘_螺纹钢"].values
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 在训练集和测试集上进行预测
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
def calculate_metrics(y_true, y_pred):
# R方分数:反映模型解释数据变异性的程度,越接近1越好
r2 = r2_score(y_true, y_pred)
# 均方根误差(RMSE):反映预测值与真实值的偏差,越小越好
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
# 平均绝对误差(MAE):反映预测值与真实值的平均差距,越小越好
mae = mean_absolute_error(y_true, y_pred)
# 平均绝对百分比误差(MAPE):反映预测误差的相对大小,越小越好
mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100
return r2, rmse, mae, mape
# 分别计算训练集和测试集的评估指标
train_metrics = calculate_metrics(y_train, y_train_pred)
test_metrics = calculate_metrics(y_test, y_test_pred)
# 打印评估结果
print("\n模型评估结果:")
print("训练集:")
print(f"R²分数: {train_metrics[0]:.4f}")
print(f"RMSE: {train_metrics[1]:.2f}")
print(f"MAE: {train_metrics[2]:.2f}")
print(f"MAPE: {train_metrics[3]:.2f}%")
print("\n测试集:")
print(f"R²分数: {test_metrics[0]:.4f}")
print(f"RMSE: {test_metrics[1]:.2f}")
print(f"MAE: {test_metrics[2]:.2f}")
print(f"MAPE: {test_metrics[3]:.2f}%")
通过图表全面展示模型表现:
# 创建评估图
plt.figure(figsize=(20, 15))
# 1. 实际值vs预测值图
plt.subplot(2, 2, 1)
plt.scatter(y_train, y_train_pred, c="blue", alpha=0.5, label="训练集")
plt.scatter(y_test, y_test_pred, c="red", alpha=0.5, label="测试集")
plt.plot([y.min(), y.max()], [y.min(), y.max()], "k--", lw=2)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值 vs 预测值")
plt.legend()
# 2. 残差图
residuals_train = y_train - y_train_pred
residuals_test = y_test - y_test_pred
plt.subplot(2, 2, 2)
plt.scatter(y_train_pred, residuals_train, c="blue", alpha=0.5, label="训练集")
plt.scatter(y_test_pred, residuals_test, c="red", alpha=0.5, label="测试集")
plt.axhline(y=0, color="k", linestyle="--")
plt.xlabel("预测值")
plt.ylabel("残差")
plt.title("残差分布图")
plt.legend()
# 3. 残差直方图
plt.subplot(2, 2, 3)
sns.histplot(residuals_train, color="blue", alpha=0.5, label="训练集", bins=30)
sns.histplot(residuals_test, color="red", alpha=0.5, label="测试集", bins=30)
plt.xlabel("残差")
plt.ylabel("频数")
plt.title("残差直方图")
plt.legend()
# 4. Q-Q图
plt.subplot(2, 2, 4)
stats.probplot(residuals_train, dist="norm", plot=plt)
plt.title("残差Q-Q图")
plt.tight_layout()
plt.show()
# 5. 添加时间序列预测图
plt.figure(figsize=(15, 7))
plt.plot(train_data["date"], train_data["收盘_螺纹钢"], 'b-', label='训练集实际值')
plt.plot(train_data["date"], y_train_pred, 'g--', label='训练集预测值')
plt.plot(test_data["date"], test_data["收盘_螺纹钢"], 'r-', label='测试集实际值')
plt.plot(test_data["date"], y_test_pred, 'y--', label='测试集预测值')
plt.axvline(x=train_data["date"].iloc[-1], color='k', linestyle='--', label='训练/测试分割点')
plt.xlabel('日期')
plt.ylabel('螺纹钢收盘价')
plt.title('时间序列预测结果')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 6. 添加散点图显示铁矿石价格与螺纹钢价格的关系
plt.figure(figsize=(10, 6))
plt.scatter(train_data["前一天铁矿石收盘"], train_data["收盘_螺纹钢"],
c="blue", alpha=0.5, label="训练集")
plt.scatter(test_data["前一天铁矿石收盘"], test_data["收盘_螺纹钢"],
c="red", alpha=0.5, label="测试集")
# 添加回归线
x_range = np.linspace(
min(df["前一天铁矿石收盘"]),
max(df["前一天铁矿石收盘"]),
100
).reshape(-1, 1)
plt.plot(x_range, model.predict(x_range), 'k-', lw=2)
plt.xlabel('前一天铁矿石收盘价')
plt.ylabel('螺纹钢收盘价')
plt.title('前一天铁矿石价格与螺纹钢价格关系')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
此为期魔方平台的内置函数,使用默认设置即可!
def get_save_model_path(file_name):
# 获取当前文件的绝对路径
current_file_path = os.path.abspath(__file__)
# 获取不带扩展名的文件名
filename_without_ext = os.path.splitext(os.path.basename(current_file_path))[0]
# 返回完整的模型保存路径
return f"{os.path.dirname(current_file_path)}\\{filename_without_ext}__{file_name}"
将训练好的模型保存到本地,以供后续模型的调试及在实盘策略中进行价格预测。
# 生成模型文件名
model_filename = get_save_model_path("经典机器学习模型-线性回归-model.qmf")
# 使用 joblib 保存模型
joblib.dump(model, model_filename)
print(f"模型已保存至: {model_filename}")
此阶段为将训练好的模型加载进来,进一步进行价格预测,比如新传入一个铁矿石价格为 800 元,让模型来预测螺纹钢的价格。
# 加载保存的模型
loaded_model = joblib.load(model_filename)
# 使用加载的模型进行预测
test_value = np.array([[800]]) # 假设前一天铁矿石价格为 800 时
predicted_price = loaded_model.predict(test_value)[0]
print("使用加载的模型预测:")
print(f"当铁矿石前一日价格为 800 时,螺纹钢当日预测价格为: {predicted_price:.2f}")
当完成了以上步骤后,您已经训练好了一个机器学习模型,下面我们以 15 分钟的机器学习预测模型为例,在策略中进行实际使用。
"""
案例
模型设定:通过铁矿石价格 15 分钟走势预测螺纹钢价格 15 分钟走势,并将结果输出到日志中
注意:本案例非交易案例,交易过程请参考策略文档进行编译
"""
# 通过 QMF 提供的多产品设置变量,设置需要的产品数据
# 详细参考 https://qmfquant.com/static/doc/code/strategyEdit.html -> BASE 全局变量
QMF_SUBSCRIBE_SYMBOLS = "I999:M15&rb999:M15"
def on_init(context):
print("[on_init] => 初始化...")
# 获取基础产品的产品 code 及周期并保存在变量中,方便后续访问使用
context.base_instrument_id = BASE_SETTING.get("Instrument")
context.period = BASE_SETTING.get("bPeriod")
# 设定一个全局的变量用于区分是否为新K线的计算使用
context.nBars_time = ""
# 加载机器学习模型
# load_model 是策略模块封装的读取模型函数,可直接读取对应相对地址
context.model = load_model('model_lr.joblib')
print("[on_init] => 初始化完成")
# 当生成了新的 K 线时,就返回真
def is_changing(context,time_array):
if context.nBars_time != time_array[-1]:
context.nBars_time = time_array[-1]
return True
return False
# 每当新的行情进来就调用 on_tick() 函数一次;
def on_tick(context):
import numpy as np
# 获取铁矿石的K线数据
# 详细参考 https://qmfquant.com/static/doc/code/strategyEdit.html -> get_kline
i999_data = get_kline("I999", "M15", 2)
# 获取螺纹钢的K线数据
# 详细参考 https://qmfquant.com/static/doc/code/strategyEdit.html -> get_kline
rb999_data = get_kline("rb999", "M15", 2)
if is_changing(context,i999_data.get("datetime")):
close_array = i999_data.get("close")
I999_close = np.array([[close_array[-1]]])
# 使用初始化时导入的模型,加载最新的铁矿石价格
# 获得模型计算后返回的预测螺纹刚价格
predicted_rb999_close = context.model.predict(I999_close)
print(f"螺纹钢的价格预测值为:{predicted_rb999_close[0]:.2f}")
rb999_close = rb999_data.get("close")
# 对比预测价格及实际价格进行后续操作计划
if predicted_rb999_close[0] > rb999_close[-1]:
print("预测的价格大于当前的实际价格,建议执行开多平空操作;")
elif predicted_rb999_close[0] < rb999_close[-1]:
print("预测的价格小于当前的实际价格,建议执行开空平多操作;")
def on_stop(context):
print("demo停止")
以上是一个机器学习预测模型在实盘策略中的应用。
| 错误类型 | 常见原因 |
|---|---|
ValueError | 参数值或数据形状错误 |
TypeError | 参数类型错误 |
AttributeError | 访问或调用不存在的属性或方法 |
NotFittedError | 在未训练的模型上调用预测方法 |
KeyError | 传递了无效的键(如超参数名称错误) |
ConvergenceWarning | 模型未收敛 |
DataConversionWarning | 数据需要隐式转换 |